OAI-SearchBot only fetched robots.txt
Table of contents
I expected OAI-SearchBot to fetch content.
It did not.
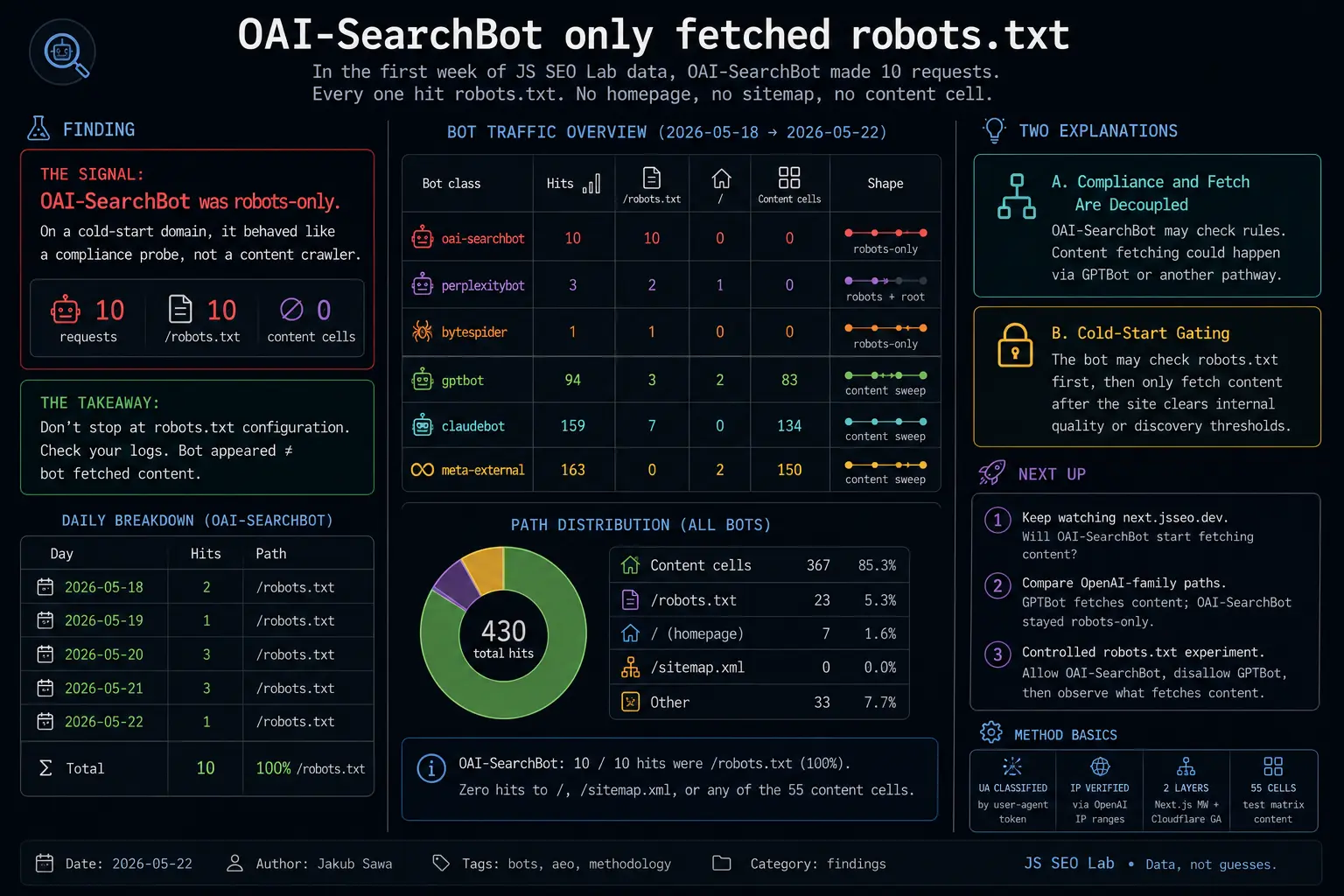
In the first week of JS SEO Lab data, OAI-SearchBot made 10 requests to the Next.js test bed. All 10 hit /robots.txt. Zero hit the homepage. Zero hit the sitemap. Zero hit any of the 55 test cells.
That is not enough data to declare how OpenAI crawls the entire web. It is enough data to say something narrower and more useful:
On this cold-start domain,
OAI-SearchBotbehaved like a compliance probe, not a content crawler.
That distinction matters, because most robots.txt advice around AI search assumes the opposite.
The Data
The test bed is next.jsseo.dev, a 55-cell matrix built to measure which JavaScript content patterns survive in bot HTTP responses. Every tracked request is logged into track.jsseo.dev through two request-observation layers: Next.js middleware for dynamic routes and a Cloudflare GraphQL Analytics ingester for static routes such as /robots.txt.
For the first live window, 2026-05-18 through 2026-05-22, the tracker saw this:
| Bot class | Hits | /robots.txt |
/ |
Content cells | Shape |
|---|---|---|---|---|---|
oai-searchbot |
10 | 10 | 0 | 0 | robots-only |
perplexitybot |
3 | 2 | 1 | 0 | robots + root |
bytespider |
1 | 1 | 0 | 0 | robots-only |
gptbot |
94 | 3 | 2 | 83 | content sweep |
claudebot |
159 | 7 | 0 | 134 | content sweep |
meta-external |
163 | 0 | 2 | 150 | content sweep |
OAI-SearchBot was the clean case. Five days, ten requests, ten robots.txt hits.
Daily breakdown:
| Day | Hits | Path |
|---|---|---|
| 2026-05-18 | 2 | /robots.txt |
| 2026-05-19 | 1 | /robots.txt |
| 2026-05-20 | 3 | /robots.txt |
| 2026-05-21 | 3 | /robots.txt |
| 2026-05-22 | 1 | /robots.txt |
No variance. No second path. No exploratory hit to /. No sitemap fetch. No cell fetch.
That contrast is the point. In the same period, GPTBot, ClaudeBot, and meta-external all found and walked content cells. They did not merely read the rulebook at the door; they entered the building. OAI-SearchBot read the rulebook and left.
Why This Is Weird
OpenAI’s own crawler documentation separates three user agents:
| User agent | Documented role |
|---|---|
GPTBot |
Automated crawling for content that may be used to improve models. |
OAI-SearchBot |
Search crawling, used to surface websites in ChatGPT search features. |
ChatGPT-User |
User-triggered fetching when someone asks ChatGPT or a Custom GPT to visit a URL. |
The natural SEO reading is: OAI-SearchBot is the crawler that fetches content for ChatGPT Search.
That is also how most AI-robots guidance frames it. Allow OAI-SearchBot if you want visibility in ChatGPT Search. Block it if you do not. Treat it separately from GPTBot, because GPTBot is about training and OAI-SearchBot is about search retrieval.
I do not think that guidance is wrong. But our logs show a shape that the guidance usually skips over:
OAI-SearchBot can show up without fetching content.
On this domain, it repeatedly fetched the robots file and stopped there.
Two Explanations
There are two clean ways to interpret this without overreaching.
Structure A: Compliance And Fetch Are Decoupled
OAI-SearchBot may be the user agent OpenAI uses to check whether search indexing is allowed, while the actual content fetch can happen through another OpenAI pathway.
That pathway might be GPTBot. It might be an internal fetcher. It might depend on site quality, URL discovery, or product surface. The important part is the architectural split: one bot reads the rule, another system fetches the page.
If this is true, the robots.txt contract is more fractured than site owners assume. A site could allow OAI-SearchBot, block GPTBot, and believe it has allowed ChatGPT Search while blocking training. But if the content fetch actually comes through GPTBot, that configuration would remove the fetch path.
This is the sharper interpretation, and the one worth watching.
It is not proven by our data. It is only consistent with it.
Structure B: Cold-Start Gating
The less dramatic explanation is that OAI-SearchBot starts by checking robots.txt, then only escalates to content fetching when a site clears some internal threshold.
next.jsseo.dev is a new experimental domain. It has no public brand demand, no meaningful backlink graph, no mature search visibility, and no reason to be high priority for ChatGPT Search. It is entirely plausible that OpenAI’s search crawler checks the rules, records consent, and waits.
If this is the right explanation, OAI-SearchBot may start fetching cells later, once the domain has more signals.
That is why I am not publishing this as “OAI-SearchBot does not crawl content.” The honest statement is smaller:
In week one, on a cold-start domain,
OAI-SearchBotwas robots-only.
Why Site Owners Should Care
The practical robots.txt advice for AI bots often says something like this:
User-agent: OAI-SearchBot
Allow: /
User-agent: GPTBot
Disallow: /
The intent is clear: allow ChatGPT Search visibility, block use in future model training.
This configuration is actively gaining traction. Cloudflare’s 2026 AI traffic commentary notes that sophisticated site owners increasingly adopt the allow-search-block-training split, on the working assumption that OAI-SearchBot is the path that drives ChatGPT referral traffic. That assumption is exactly what the data above puts under tension.
That intent depends on one assumption: OAI-SearchBot is the content-fetching path for search.
Our data does not disprove that assumption globally. It does show that the presence of OAI-SearchBot in your logs is not, by itself, evidence that OpenAI fetched your content for search. In our case, the bot was present. It just never left /robots.txt.
So the operational advice becomes more boring, and more useful:
Do not stop at robots.txt configuration. Check your logs.
Specifically:
- Look for
OAI-SearchBotrequests beyond/robots.txt. - Separate robots-file checks from page fetches.
- Compare
OAI-SearchBotpaths withGPTBotpaths. - Verify that claimed OpenAI user agents come from OpenAI’s published IP ranges.
- Treat “bot appeared” and “bot fetched content” as different events.
A crawler policy is not real until traffic confirms it.
What Would Falsify This
This is a single-domain, low-volume finding. Three things would weaken or kill it.
First, OAI-SearchBot may start fetching content on next.jsseo.dev in week two, week three, or after the domain gains stronger discovery signals. If that happens, the cold-start explanation wins.
Second, someone may show access logs from an established site where OAI-SearchBot clearly fetches article, product, or category URLs. After publishing, I went back and looked at every public dataset on OAI-SearchBot I could find. Three independent aggregate studies — Hostinger / ALM (279M OAI-SearchBot requests across 5M sites in 2025), Botify (post-GPT-5 OAI-SearchBot volume reaching parity with GPTBot at a 1.14 ratio), and Digital Applied (~1,400 OAI-SearchBot requests per site per day across a 12-site panel) — report volumes that cannot be explained by robots.txt polling alone. None of them publishes the per-path breakdown that would directly confirm or refute “robots-only on cold-start domains”, but the arithmetic is informative on its own: at established-site scale, OAI-SearchBot clearly fetches more than the robots file. The cold-start framing is the version of this finding consistent with both our 10 rows and the public aggregates. I would still like to see a raw per-path log slice from an established site.
Third, OpenAI may clarify the architecture. Their docs already say they may use results from one crawl for multiple use cases to avoid duplicate crawling. That line matters. It leaves room for shared crawl infrastructure where the visible user-agent boundary is not the whole story.
If you have logs where OAI-SearchBot fetched real content paths, I want to see them. Not screenshots of documentation. Actual path-level logs.
What I Am Holding Back
I am not claiming:
OAI-SearchBotnever fetches content.- Allowing
OAI-SearchBotis useless. - OpenAI’s documentation is wrong.
GPTBotis definitely the hidden content fetch path for ChatGPT Search.
Those would all be too strong for ten rows from one cold-start domain.
What I am claiming:
- In this first window,
OAI-SearchBotmade 10 requests. - All 10 were
/robots.txt. - Other AI/search bots in the same tracker window did fetch content cells.
- Therefore, on this domain,
OAI-SearchBotbehaved as a robots/compliance probe, not as a content crawler.
That is enough to justify a better question:
When you allow
OAI-SearchBot, which OpenAI system actually fetches the page?
Method Notes
The classifier assigns oai-searchbot from the user-agent string using the OAI-SearchBot token. OpenAI publishes IP ranges for this crawler at openai.com/searchbot.json; the tracker verifies OpenAI-family bots through IP-range matching.
The robots file on next.jsseo.dev is permissive:
User-agent: *
Allow: /
So this is not a case where OAI-SearchBot hit a blocked rule and went away. It had permission to fetch content.
The tracker can see /robots.txt because Cloudflare Analytics ingestion catches static routes that bypass the Next.js middleware. That matters here: without Layer 2, this finding would be invisible.
The limitation is also clear. We are measuring one domain in its first week of life. Cold-start behaviour may not generalize to established sites.
What I Will Watch Next
Three follow-ups are now on the board.
First, keep watching next.jsseo.dev. If OAI-SearchBot starts fetching cells, the timeline matters: how many days after first robots hit, and after which discovery event?
Second, compare OpenAI-family paths. If GPTBot keeps sweeping content while OAI-SearchBot remains robots-only, the compliance/fetch split becomes more plausible.
Third, run a controlled robots.txt side experiment later in Phase 1: allow OAI-SearchBot, disallow GPTBot, then watch whether any OpenAI verified IP fetches content. That is the test that can move this from “interesting observation” to “practical crawler policy finding.”
Fourth, cross-check the 10 hits against OpenAI’s published searchbot.json IP ranges. The tracker already pulls OpenAI IP lists for GPTBot verification; extending that to searchbot ranges is a one-config-line change. If any of the 10 robots-only hits come from outside the published ranges, this finding gets a UA-spoof asterisk.
For now, the lesson is simple:
Robots.txt tells crawlers what they may do. Logs tell you what they actually did.
In our first week, OAI-SearchBot read the rules and walked away.
Data availability: JS SEO Lab publishes methodology and tracker notes in the public repository at github.com/Qbeczek1/jsseo-dev. The live aggregate dashboard is available at /dashboard/.
Bias disclosure: I run JS SEO Lab as an independent technical SEO research project. I also do paid technical SEO and AI visibility audits through FratreSEO. No framework vendor, crawler vendor, search engine, or AI company funds this work.