Most AI batch crawlers never fetched our robots.txt
Table of contents
I expected every well-behaved crawler to fetch /robots.txt before walking the site.
Most of them did not.
In the first 15 days of JS SEO Lab data on next.jsseo.dev, the tracker recorded 6,125 HTTP hits across 25 user-agent classes. Bots crawled all 55 test cells in the matrix. Yet six of the highest-volume bot classes — gptbot, google-readaloud, meta-external, amazonbot, google-other, google-inspection — together produced 862 hits without a single request to /robots.txt during the window.
In our data, in this window, the absence of a
/robots.txtrequest in your access logs does not tell you whether a crawler checked the rules.
That phrasing matters. I am not saying these crawlers ignore robots.txt. I am saying that on this domain, in this window, they never fetched it — and they still found their way to content cells. Where the rule-check actually happened (or whether it happened at all) is not something a standard access log can answer.
The Data
The test bed is next.jsseo.dev, a 55-cell matrix that measures which JavaScript content patterns survive in bot HTTP responses. Every request is logged into track.jsseo.dev through three layers: Next.js middleware for dynamic routes, a Cloudflare GraphQL Analytics poller for static routes (which is the path through which /robots.txt and /sitemap.xml hits are captured), and a JS-execution beacon for measuring actual JS execution.
For the window 2026-05-18 12:37 UTC → 2026-06-02 11:40 UTC (14d 23h), the snapshot looked like this:
| Metric | Value |
|---|---|
| Total hits | 6,125 |
| Distinct user-agent classes | 25 |
| Distinct raw User-Agent strings | 177 |
| Test cells touched (out of 55) | 55 |
| Layer 3 JS-execution beacon firings | 167 |
The site’s robots.txt is permissive — User-agent: * Allow: / with a single sitemap declaration. Nothing in this finding is explained by rule denial.
The Roster
Removing self-traffic from the count is important. The human class (2,735 hits) is dominated by me operating the site, the security-scanner class (868 hits — none on cells, all on common vuln paths) and cf-internal class (453 hits from Cloudflare’s own infrastructure probes) are noise from a public-facing IP. The non-self, non-noise crawler roster, sorted by hits, looks like this:
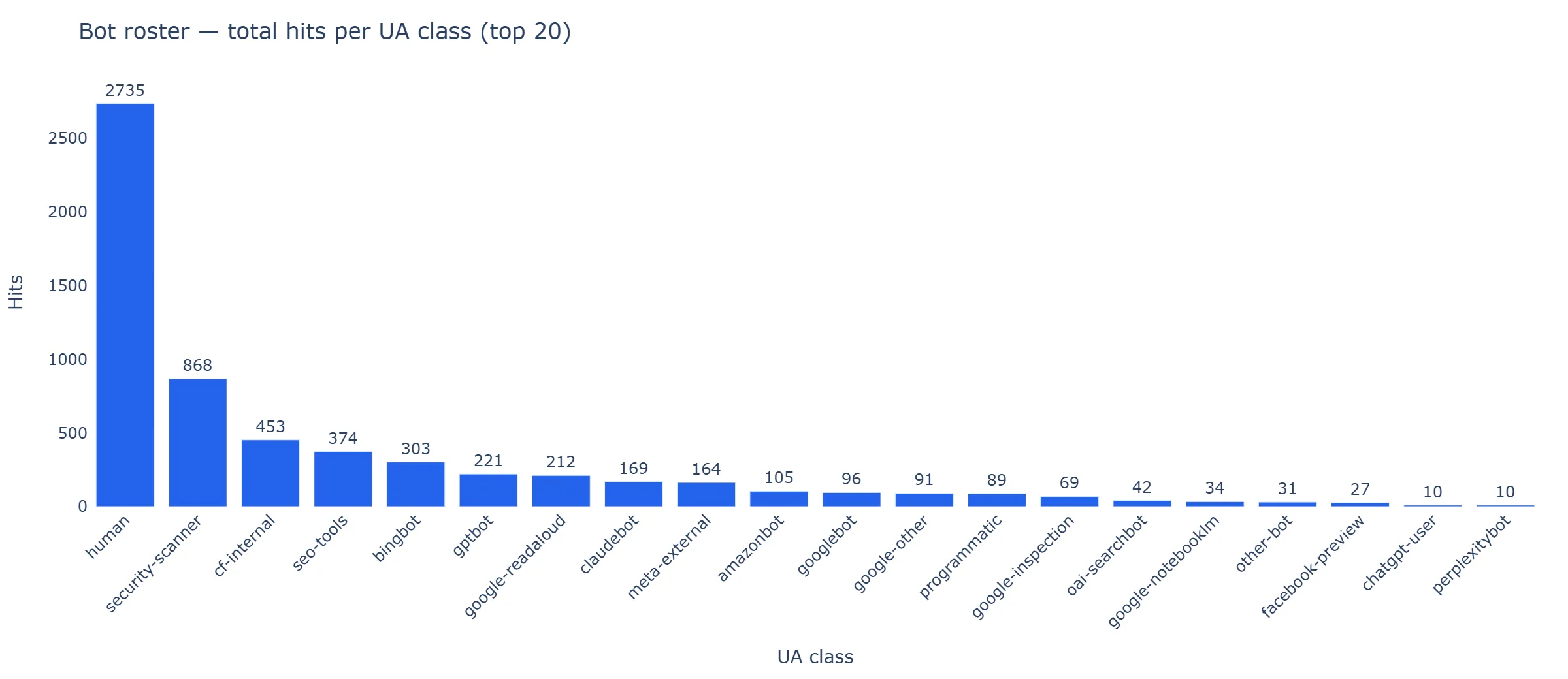 Figure 1 — Hits per UA class, top 20.
Figure 1 — Hits per UA class, top 20. human, security-scanner and cf-internal dominate the tall left-hand bars; the bot crawlers we care about for this finding start at bingbot (303 hits) and run through to the long tail.
| UA class | Hits | Distinct IPs | Cells | Verified | First seen | Last seen |
|---|---|---|---|---|---|---|
bingbot |
303 | 106 | 30 | 303 | 2026-05-18 19:45 | 2026-06-02 11:36 |
gptbot |
221 | 6 | 39 | 217 | 2026-05-18 14:05 | 2026-06-01 15:42 |
google-readaloud |
212 | 42 | 17 | 212 | 2026-05-18 15:27 | 2026-05-31 17:56 |
claudebot |
169 | 9 | 55 | 0 | 2026-05-18 15:53 | 2026-05-27 16:56 |
meta-external |
164 | 50 | 55 | 0 | 2026-05-18 16:07 | 2026-05-30 13:25 |
amazonbot |
105 | 54 | 39 | 0 | 2026-05-21 20:17 | 2026-05-28 19:00 |
googlebot |
96 | 10 | 9 | 94 | 2026-05-18 15:00 | 2026-05-27 16:56 |
google-other |
91 | 6 | 34 | 91 | 2026-05-20 05:08 | 2026-05-27 09:28 |
google-inspection |
69 | 5 | 5 | 61 | 2026-05-18 15:00 | 2026-05-22 12:26 |
oai-searchbot |
42 | 13 | 1 | 38 | 2026-05-18 14:05 | 2026-06-02 04:09 |
(Verified counts hits where reverse-DNS or IP-range verification confirmed the requester. Crawlers without a verification path — currently the claude* and meta-* classes — sit at zero verified by design, not by failure.)
The claudebot and meta-external classes hit all 55 test cells. gptbot and amazonbot covered 39 each. The matrix coverage tells one story: the AI batch crawlers in our window are doing near-exhaustive sweeps. The robots.txt funnel, below, tells a different one.
A note on the human bucket
The human row in the roster table above shows 2,735 hits — that is the raw output of the classifier and it is materially impure. A first pass over the underlying user-agent strings shows that 200+ of those hits are explicitly named scanners or scrapers the current classifier misses (Palo Alto Cortex Xpanse, CensysInspect, CMS-Checker, HeadlessChrome, a truncated Mozilla/...AppleWebKit UA used by a primitive crawler). A larger share — including a 177-IP pool all sharing an iOS 13.2.3 Safari UA from late 2019, and a handful of single-IP scrapers running years-old Chrome versions on dozens of paths — is harder to catch with a regex classifier but is almost certainly not human either.
The classifier patch addressing the 200+ explicit cases is already merged. The residual contamination (stale-browser-version detection, botnet UA-pool detection) is the subject of a separate finding post planned for the coming days, after the patched classifier has produced a clean comparison window.
For this post: every claim about a bot class other than human is unaffected. The human row should be read as a soft upper bound on real human traffic, not as the real number.
Three Robots.txt Behaviours
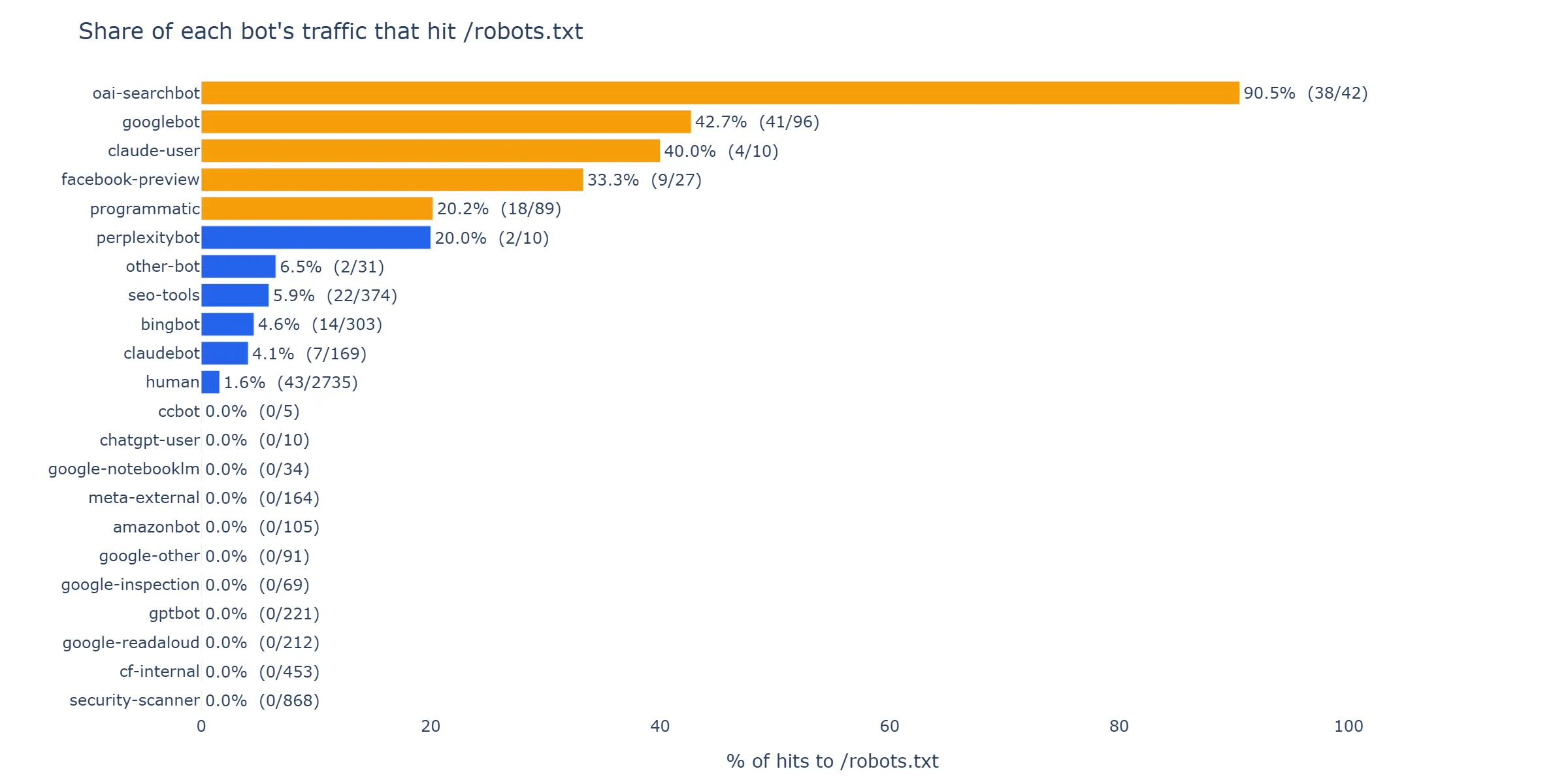
Group each bot’s hits by url_path == '/robots.txt' and compute the share of its total traffic that hit the rulebook. Three distinct bands emerge.
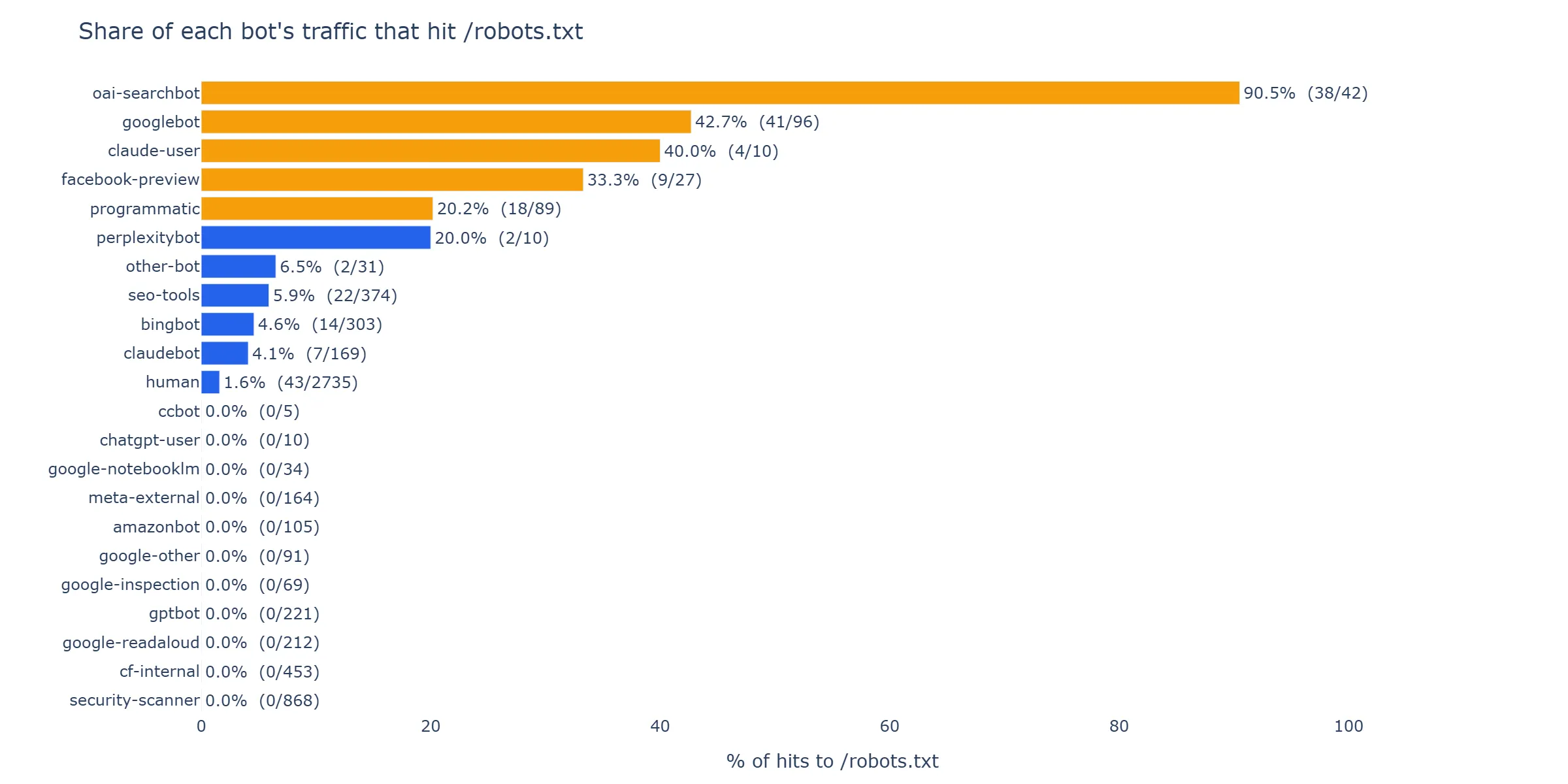 Figure 2 — Share of each UA class’s hits that landed on
Figure 2 — Share of each UA class’s hits that landed on /robots.txt. Three bands: heavy readers at the right (oai-searchbot 90.5%, googlebot 42.7%), light readers in the middle (seo-tools, bingbot, claudebot at 4–6%), and a long left-hand stack of UA classes with hard-zero robots.txt fetches across the window. Filtered to classes with ≥5 hits.
Band 1 — Heavy readers (robots.txt share > 20%):
| UA class | Hits | /robots.txt |
Share |
|---|---|---|---|
oai-searchbot |
42 | 38 | 90.5% |
googlebot |
96 | 41 | 42.7% |
oai-searchbot continues the pattern we first reported on May 22nd: a near-pure compliance probe. In the new 15-day window it added one new behaviour — two of its 42 hits actually touched a content cell — but 38 of 42 hits are still robots.txt, from 12 of 13 distinct IPs. Whatever it is doing, it is overwhelmingly there to read the rulebook.
googlebot’s 42.7% is the surprise. Forty-one of its 96 hits landed on /robots.txt. Our robots.txt is a single static file that has not changed since deploy. Two readings of the same data: (a) googlebot is re-fetching aggressively because it sees next.jsseo.dev as a new property under active discovery and is poking at the rules repeatedly during onboarding; (b) something about the Cloudflare Pages response headers is causing Google not to cache the file. We cannot separate those from our side.
Band 2 — Light readers (1% < robots.txt share < 20%):
| UA class | Hits | /robots.txt |
Share |
|---|---|---|---|
seo-tools |
374 | 22 | 5.9% |
bingbot |
303 | 14 | 4.6% |
claudebot |
169 | 7 | 4.1% |
These three sit in the same 4–6% band. They fetch robots.txt occasionally but most of their traffic is content. The seo-tools class is dominated by Majestic’s MJ12bot; bingbot is the one we already broke into desktop and smartphone subsystems; claudebot is Anthropic’s batch crawler.
Band 3 — Zero readers (no /robots.txt request in the entire window):
| UA class | Hits | Cells covered | /robots.txt |
/sitemap.xml |
|---|---|---|---|---|
gptbot |
221 | 39 | 0 | 14 |
google-readaloud |
212 | 17 | 0 | 0 |
meta-external |
164 | 55 | 0 | 1 |
amazonbot |
105 | 39 | 0 | 1 |
google-other |
91 | 34 | 0 | 0 |
google-inspection |
69 | 5 | 0 | 4 |
| Total | 862 | 0 | 20 |
Six UA classes. 862 hits. Zero /robots.txt requests. Together they fetched 713 content cells, walked the site, and never asked for the rulebook.
gptbot is the loudest case. 221 hits, 39 of the 55 cells covered, 14 sitemap fetches, zero robots fetches. It walked the test bed for the entire window without once asking for /robots.txt.
meta-external is the broadest in IP footprint: 50 distinct source IPs, each hitting one to four content cells, none of them touching /robots.txt. Same shape for amazonbot: 54 IPs, every one of them went straight to content.
The Per-IP Funnel
The hit-level share is one view. The session-level view (with “session” defined as “all hits from one source IP, ordered by timestamp”) is a second view, and it sharpens the contrast.
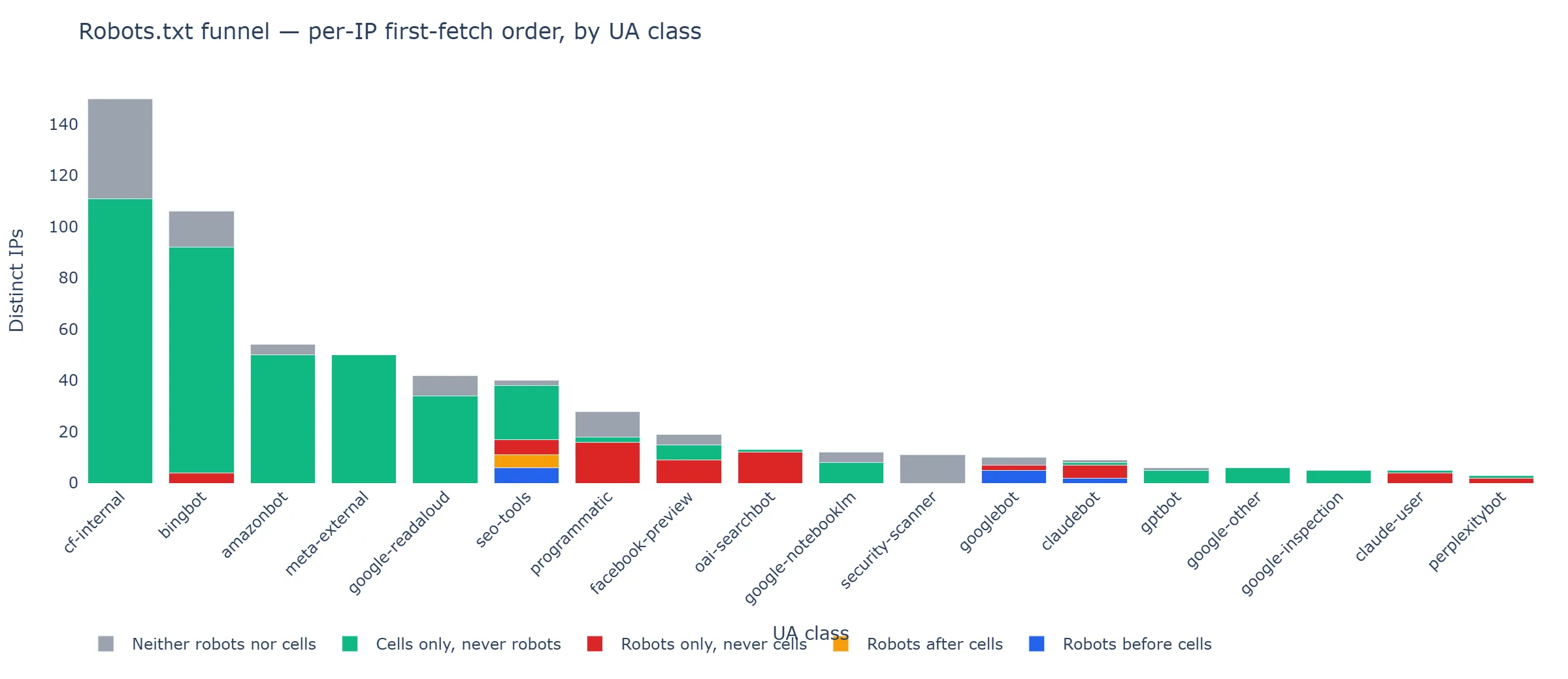 Figure 3 — Per-IP funnel categories. For each UA class, every distinct source IP is classified into one of five buckets: robots before cells (blue), robots after cells (yellow), robots only / never cells (red), cells only / never robots (green), or neither (grey). Most batch crawlers’ IPs sit in the green bar — entire sessions that fetched content without ever requesting
Figure 3 — Per-IP funnel categories. For each UA class, every distinct source IP is classified into one of five buckets: robots before cells (blue), robots after cells (yellow), robots only / never cells (red), cells only / never robots (green), or neither (grey). Most batch crawlers’ IPs sit in the green bar — entire sessions that fetched content without ever requesting /robots.txt.
A few highlights from the raw data:
meta-external: 50 distinct IPs, all 50 in the “cells only, never robots” bucket. Every single Meta IP in our window crawled content without first checking the rules.amazonbot: 54 distinct IPs, 50 in “cells only”, 4 in “neither” (hit neither robots.txt nor a cell, presumably on some other path). Zero in any robots-touching bucket.gptbot: 6 distinct IPs, 5 in “cells only”, 1 in “neither”. The same shape, but with a tighter IP footprint (6 IPs * 221 hits = ~37 hits per IP average — GPTBot’s pool is small and busy).googlebot: 10 distinct IPs, 5 in “robots before cells”, 2 in “robots only”, 3 in “cells only”, 0 in “robots after cells”. Half of Googlebot’s IPs fetched robots.txt before any cell — none of them fetched it after, suggesting that when Googlebot reads the rules, it reads them up front.oai-searchbot: 13 distinct IPs, 12 in “robots only”, 1 in “cells only”. The robots-only shape from the earlier finding holds at the session level too.claudebot: 9 distinct IPs, 2 “robots before”, 5 “robots only”, 1 “cells only”, 1 “neither”. The most varied behaviour of any AI batch crawler in our data — Anthropic’s pool is doing different things from different IPs.
The cell-coverage row makes one thing harder to dismiss. claudebot and meta-external both hit all 55 cells. meta-external did this from 50 distinct IPs, none of them fetching /robots.txt. Whatever rule-checking happens for Meta’s content crawler, it is not visible in the access log of the site being crawled.
What This Doesn’t Prove
Three things this data does not establish.
It does not prove these crawlers ignored robots.txt. Several vendor documentation pages — OpenAI’s GPTBot page, Meta’s web-crawler page, Amazon’s Amazonbot page — state that the crawlers respect robots.txt. There is a plausible architecture in which a crawler’s dispatcher fetches robots.txt centrally (off the visible IP pool, or once across many domains, or out-of-band against a cached version), evaluates the rules, and dispatches the cell-fetching IPs only if allowed. Under that architecture, the per-domain access log of the destination site would never see a /robots.txt request — but the rules would still have been checked.
We cannot distinguish that architecture from “the crawler just doesn’t bother” using this data. Both would produce the same access-log shape.
It does not prove anything about other domains. This is one cold-start research site, 15 days, low-popularity. A site with prior crawl history, more inbound links, or a non-permissive robots.txt might receive completely different behaviour from the same crawlers.
The discovery path for the cells is opaque. gptbot covered 39 cells from 6 IPs without ever fetching robots.txt or fetching any cell URL from / or a top-level navigation. I did not submit next.jsseo.dev to OpenAI, Meta, or Amazon through any documented submission channel; the discovery happened on the crawler’s side. Three plausible paths: (a) a centralized discovery system that read robots.txt and the sitemap on a different IP/UA than the cell-fetcher, (b) sitemap.xml fetched by convention without first reading robots.txt (we saw 14 sitemap.xml fetches from gptbot, 1 each from meta-external and amazonbot), or © link discovery from another domain that links to the test bed. We cannot pick between them from the access log alone.
The Daily Shape
For completeness — bot activity is bursty, not steady. The day-by-day breakdown shows it clearly.
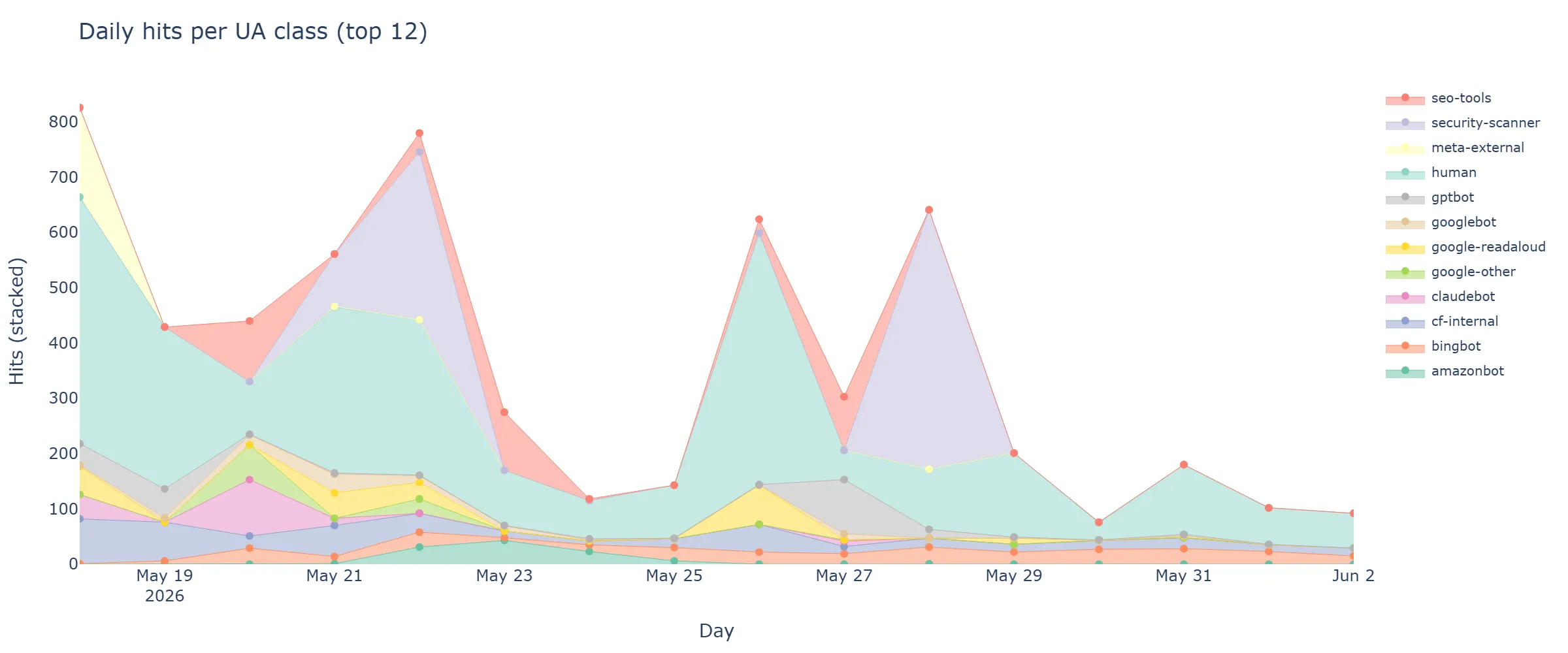 Figure 4 — Daily hits per UA class (top 12 classes, stacked). The first three days (2026-05-18 → 20) are dominated by the initial discovery sweep; AI batch crawlers concentrate their activity in 1–3 day windows rather than steady-state daily crawl.
Figure 4 — Daily hits per UA class (top 12 classes, stacked). The first three days (2026-05-18 → 20) are dominated by the initial discovery sweep; AI batch crawlers concentrate their activity in 1–3 day windows rather than steady-state daily crawl.
Each AI batch crawler made its primary sweep within the first few days of the deployment and then went largely quiet. gptbot was most active on day one (2026-05-18) and day 14 (2026-06-01) with little in between. claudebot did its main sweep on 2026-05-19 and a smaller one on 2026-05-27, then stopped. meta-external similarly front-loaded. Whatever continuous-crawl mental model you have for these bots, it is probably not what the data shows on a cold-start domain.
Cell Coverage by Pattern
Cross-cutting check: which JavaScript content patterns did each bot reach? Eight patterns × ~7 cells per pattern average. Coverage per (bot × pattern):
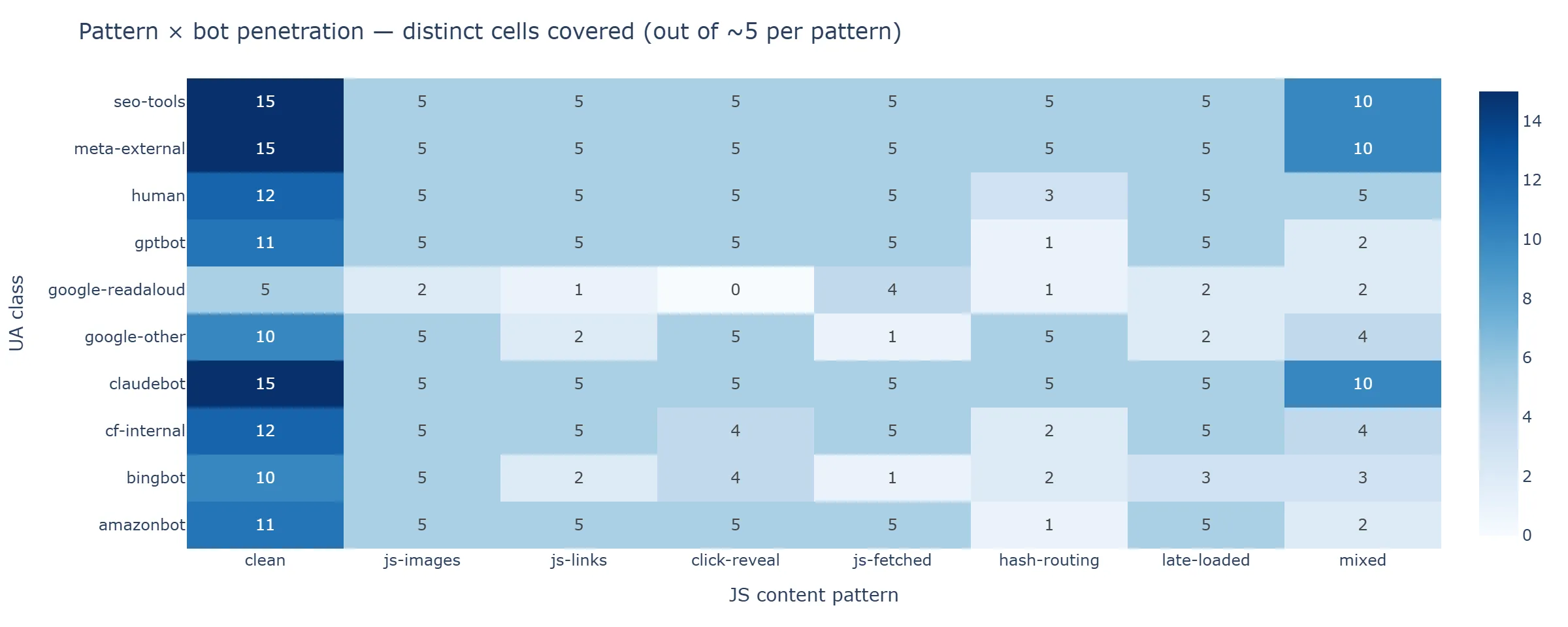 Figure 5 — Pattern × bot penetration heatmap. Each cell shows the distinct cell-marker count that UA class touched within each JS content pattern (out of ~7 cells per pattern). Darker cells = broader coverage.
Figure 5 — Pattern × bot penetration heatmap. Each cell shows the distinct cell-marker count that UA class touched within each JS content pattern (out of ~7 cells per pattern). Darker cells = broader coverage. claudebot, meta-external, and seo-tools come closest to uniform sweep across the matrix; googlebot is the most selective.
Three of the AI batch crawlers (claudebot, meta-external, seo-tools) come close to uniform full-matrix sweep. gptbot skips a few patterns. googlebot is sharply selective — 9 cells total — but the selection includes both clean and several JS-content-dependent patterns. This last shape is the one to keep in mind when reading the earlier finding on Googlebot WRS being SSR-content-only on csr/mixed/homepage — that finding describes JavaScript rendering behaviour given that Googlebot visited; this chart describes what it visited at all.
What This Means For Site Owners
A short, boring list.
Do not infer compliance from log absence. “I never see GPTBot fetching /robots.txt, therefore it must be ignoring my rules” is not a valid inference. The bot may be checking your rules out-of-band, off this IP pool, against a cached version, or via a different system entirely. The fetch you can see is not the fetch you can audit.
Conversely, a high robots.txt fetch rate is not necessarily good news. googlebot at 42.7% on a static file is also worth raising an eyebrow at — it may indicate either active onboarding or some cache misbehaviour. Neither is operationally great if it continues for months. If you have a similar share on a static robots.txt, it is worth a closer look at your response headers.
The rule-check mechanism for AI batch crawlers is not testable from your access log. If you need to know whether a given crawler is respecting your Disallow: directives, the way to find out is to actually disallow it and watch whether the cell fetches stop. Inferring from “did it fetch robots.txt?” tells you nothing about compliance — it tells you about the architecture of the crawler’s request dispatcher.
I plan to run exactly that test in a future window — switch the test bed robots.txt to disallow GPTBot, Meta, and Amazon for a defined cell subset, and watch whether their cell fetches stop. A finding either way will tell us something we cannot tell from this snapshot.
What I Am Not Claiming
- That GPTBot, Meta-external, or Amazonbot ignore robots.txt. The data shows what their per-domain access logs look like, not what their global rule-evaluation does.
- That OAI-SearchBot does not crawl content. In this window it touched 2 cells, up from the zero we observed in the May 18–22 window. The “robots-only” framing is now narrower: dominant but not absolute.
- That Googlebot’s 42.7% robots-fetch rate is unusual for all Google-tracked properties. This is one cold-start domain at one phase of Google’s awareness of it.
- That the rule-evaluation architecture I sketched (“centralized fetch, distributed cell fetch”) is what these crawlers actually do. It is one consistent interpretation among others.
What Would Falsify This
The simplest falsifier is a Disallow: test. Add a per-bot Disallow: /ssr/clean/article (or any specific cell) to robots.txt, wait one to two weeks, and observe.
- If
gptbot/meta-external/amazonbotcontinue to fetch the disallowed cell at the same rate, “they are ignoring the rules” becomes the parsimonious interpretation, and this finding gets considerably stronger. - If they stop fetching the disallowed cell, without ever fetching
/robots.txtfrom any visible IP, then “they are checking rules out-of-band” gains direct evidence. That outcome is the more interesting one. - If they stop fetching the cell and start fetching
/robots.txt, then the rule update was the trigger for an on-domain rule fetch — also informative.
A second falsifier: a larger longitudinal sample. If after another month of observation gptbot is still at 0/n on robots.txt across hundreds more hits, the per-domain-zero-fetch pattern firms up. If it dips robots.txt even once, the absoluteness weakens, even if the share stays low.
A third: someone with bigger logs running the same query. A 6,125-hit sample is small. If a publisher with millions of monthly bot hits runs SELECT user_agent, COUNT(*), SUM(url_path = '/robots.txt') / COUNT(*) FROM hits GROUP BY user_agent and the band structure looks different, the bands in our data are probably an artifact of cold-start scale.
Method Notes
The bucket classification used url_path == '/robots.txt' exact match. There is no soft match — anyone fetching /robots.txt?v=1 or /robots would have been counted elsewhere, but a scan of the data shows no such variants in our window.
The session funnel groups hits by ip_hash (SHA-256 of the source IP plus a fixed salt — see TRACKER.md) rather than by a logical session token. For most batch crawlers, one IP corresponds to one fetcher, so this approximation holds; for crawlers using NAT’d pools (we have not confirmed which here) the funnel categories could mis-attribute concurrent sessions to the same IP.
UA classification is via classifier.js regex match. Verification is via reverse-DNS (googlebot, bingbot, applebot, google-readaloud, google-other, google-inspection) or IP-range check against published vendor manifests (gptbot, oai-searchbot, perplexitybot). The claude* and meta-* classes have no verification path at the time of writing — vendor manifests are not yet published in the format the verifier consumes, so verified=0 here means “not yet checked,” not “spoofed.”
The tracker captures /robots.txt and /sitemap.xml via the Cloudflare GraphQL Analytics ingester (Layer 2). The Next.js middleware (Layer 1) intentionally skips non-cell paths, so without Layer 2 we would not see these fetches at all. The 60-second poll lag means the absolute end-of-window count for the last minute may undercount by a hit or two; for a 6,125-hit window this is below the level of any claim we are making.
The 5 charts in this post were generated from the SQLite snapshot taken at 2026-06-02 11:55 UTC using scripts/analysis/analyze.py. The interactive HTML version of all charts (with hover details) is also produced by that script.
Data availability: JS SEO Lab publishes methodology, tracker code, classifier, and findings notes in the public repository at github.com/Qbeczek1/jsseo-dev. The live aggregate dashboard is at /dashboard/.
Bias disclosure: I run JS SEO Lab as an independent technical SEO research project. I also do paid technical SEO and AI visibility audits through FratreSEO. No framework vendor, crawler vendor, search engine, or AI company funds this work.